Cause prioritization for downside-focused value systems
Summary
This post outlines my thinking on cause prioritization from the perspective of value systems whose primary concern is reducing disvalue. I’m mainly thinking of suffering-focused ethics (SFE), but I also want to include moral views that attribute substantial disvalue to things other than suffering, such as inequality or preference violation. I will limit the discussion to interventions targeted at improving the long-term future (see the reasons in section II). I hope my post will also be informative for people who do not share a downside-focused outlook, as thinking about cause prioritization from different perspectives, with emphasis on considerations other than those one is used to, can be illuminating. Moreover, understanding the strategic considerations for plausible moral views is essential for acting under moral uncertainty and cooperating with people with other values.
I will talk about the following topics:
- Which views qualify as downside-focused (given our empirical situation)
- Why downside-focused views prioritize s-risk reduction over utopia creation
- Why extinction risk reduction is unlikely to be a promising intervention according to downside-focused views
- Why AI alignment is probably positive for downside-focused views, and especially positive if done with certain precautions
- What to include in an EA portfolio that incorporates population ethical uncertainty and cooperation between value systems
Contents
- Which views qualify as downside-focused?
- Most expected disvalue happens in the long-term future
- Downside-focused views prioritize s-risk reduction over utopia creation
- Extinction risk reduction: Unlikely to be positive according to downside-focused views
- AI alignment: (Probably) positive for downside-focused views; high variance
- Moral uncertainty and cooperation
- Acknowledgements
- References
- Endnotes
Which views qualify as downside-focused?
I’m using the term downside-focused to refer to value systems that in practice (given what we know about the world) primarily recommend working on interventions that make bad things less likely.1 For example, if one holds that what is most important is how things turn out for individuals (welfarist consequentialism), and that it is comparatively unimportant to add well-off beings to the world, then one should likely focus on preventing suffering.2 That would be a downside-focused ethical view.
By contrast, other moral views place great importance on the potential upsides of very good futures, in particular with respect to bringing about a utopia where vast numbers of well-off individuals will exist. Proponents of such views may also believe it to be a top priority that a large, flourishing civilization exists for an extremely long time. I will call these views upside-focused.
Upside-focused views do not have to imply that bringing about good things is normatively more important than preventing bad things; instead, a view also counts as upside-focused if one has reason to believe that bringing about good things is easier in practice (and thus more overall value can be achieved that way) than preventing bad things.
A key point of disagreement between the two perspectives is that the upside-focused people might say that suffering and happiness are in a relevant sense symmetrical, and that downside-focused people are too willing to give up good things in the future, such as the coming into existence of many happy beings, just to prevent suffering. On the other side, downside-focused people feel that the other party is too willing to accept, say, that many people suffering extremely goes unaddressed, or is in some sense being accepted in order to achieve some purportedly greater good.
Whether a normative view qualifies as downside-focused or upside-focused is not always easy to determine, as the answer can depend on difficult empirical questions such as how much disvalue we can expect to be able to reduce versus how much value we can expect to be able to create. I feel confident however that views according to which it is not in itself (particularly) valuable to bring beings in optimal conditions into existence come out as largely downside-focused. The following commitments may lead to a downside-focused prioritization:
- Views based on tranquilist axiology
- Views based on “negative-leaning” variants of traditional consequentialist axiology (hedonist axiology)3
- Prioritarianism or welfare-based egalitarianism4
- Antifrustrationism
- Views that incorporate some (asymmetric) person-affecting principle5
- (Non-welfarist) views that include considerations about suffering prevention or the prevention of rights violations as a prior or as (central) part of an objective list of what constitutes goodness
For those who are unsure about where their beliefs may fall on the spectrum between downside- and upside-focused views, and how this affects their cause prioritization with regard to the long-term future, I recommend being on the lookout for interventions that are positive and impactful according to both perspectives. Alternatively, one could engage more with population ethics to perhaps cash in on the value of information from narrowing down one’s uncertainty.
Most expected disvalue happens in the long-term future
In this post, I will only discuss interventions chosen with the intent of affecting the long-term future – which not everyone agrees is the best strategy for doing good. I want to note that choosing interventions that reliably reduce suffering or promote well-being in the short run also has many arguments in its favor.
Having said that, I believe that most of the expected value comes from the effects our actions have on the long-term future, and that our thinking about cause prioritization should explicitly reflect this. The future may come to hold astronomical quantities of the things that people value (Bostrom, 2003). Correspondingly, for moral views that place a lot of weight on bringing about astronomical quantities of positive value (e.g., happiness or human flourishing), Nick Beckstead presented a strong case for focusing on the long-term future. For downside-focused views, that case rests on similar premises. A simplified version of that argument is based on the two following ideas:
- Some futures contain astronomically more disvalue than others, such as uncontrolled space colonization versus a future where compassionate and wise actors are in control.
- It is sufficiently likely that our current actions can help shape the future so that we avoid worse outcomes and end up with better ones. For example, such an action could be to try to figure out which interventions best improve the long-term future.
This does not mean that one should necessarily pick interventions one thinks will affect the long-term future through some specific, narrow pathway. Rather, I am saying (following Beckstead) that we should pick our actions based primarily on what we estimate their net effects to be on the long-term future.6 This includes not only narrowly targeted interventions such as technical work in AI alignment, but also projects that improve the values and decision-making capacities in society at large to help future generations cope better with expected challenges.
Downside-focused views prioritize s-risk reduction over utopia creation
The observable universe has very little suffering (or inequality, preference frustration, etc.) compared to what could be the case; for all we know suffering at the moment may only exist on one small planet in a computationally inefficient form of organic life.7 According to downside-focused views, this is fortunate, but it also means that things can become much worse. Suffering risks (or “s-risks”) are defined as events that bring about suffering in cosmically significant amounts. By “significant”, we mean significant relative to expected future suffering.8 Analogously and more generally, we can define downside risks as events that would bring about disvalue (including things other than suffering) at vastly unprecedented scales.
Why might this definition be practically relevant? Imagine the hypothetical future scenario “Business as usual (BAU),” where things continue onwards indefinitely exactly as they are today, with all bad things being confined to earth only. Hypothetically, let’s say that we expect 10% of futures to be BAU, and we imagine there was an intervention – let’s call it paradise creation – that changed all BAU futures into futures where a suffering-free paradise is created. Let us further assume that another 10% of futures will be futures where earth-originating intelligence colonizes space and things go very wrong such that, through some pathway or another, creates vastly more suffering than has ever existed (and would ever exist) on earth, and little to no happiness or good things. We will call this second scenario “Astronomical Suffering (AS).”
If we limit our attention to only the two scenarios AS and BAU (of course there are many other conceivable scenarios, including scenarios where humans go extinct or where space colonization results in a future filled with predominantly happiness and flourishing), then we see that the total suffering in the AS futures vastly exceeds all the suffering in the BAU futures. Successful paradise creation therefore would have a much smaller impact in terms of reducing suffering than an alternative intervention that averts the 10% s-risk from the AS scenario, changing it to a BAU scenario for instance. Even reducing the s-risk from AS in our example by a single percentage point would be vastly more impactful than preventing the suffering from all the BAU futures.
This consideration highlights why suffering-focused altruists should probably invest their resources not into making very good outcomes more likely, but rather into making dystopian outcomes (or dystopian elements in otherwise good outcomes) less likely. Utopian outcomes where all suffering is abolished through technology and all sentient beings get to enjoy lives filled with unprecedented heights of happiness are certainly something we should hope will happen. But from a downside-focused perspective, our own efforts to do good are, on the margin, better directed towards making it less likely that we get particularly bad futures.
While the AS scenario above was stipulated to contain little to no happiness, it is important to note that s-risks can also affect futures that contain more happy individuals than suffering ones. For instance, the suffering in a future with an astronomically large population count where 99% of individuals are very well off and 1% of individuals suffer greatly constitutes an s-risk even though upside-focused views may evaluate this future as very good and worth bringing about. Especially when it comes to the prevention of s-risks affecting futures that otherwise contain a lot of happiness, it matters a great deal how the risk in question is being prevented. For instance, if we envision a future that is utopian in many respects except for a small portion of the population suffering because of problem x, it is in the interest of virtually all value systems to solve problem x in highly targeted ways that move probability mass towards even better futures. By contrast, only few value systems (ones that are strongly or exclusively about reducing suffering/bad things) would consider it overall good if problem X was “solved” in a way that not only prevented the suffering due to problem X, but also prevented all the happiness from the future scenario this suffering was embedded in. As I will argue in the last section, moral uncertainty and moral cooperation are strong reasons to solve such problems in ways that most value systems approve of.
All of this is based on the assumption that bad futures, i.e., futures with severe s-risks or downside risks, are reasonably likely to happen (and can tractably be addressed). This seems to be the case, unfortunately: We find ourselves on a civilizational trajectory with rapidly growing technological capabilities, and the ceilings from physical limits still far away. It looks as though large-scale space colonization might become possible someday, either for humans directly, for some successor species, or for intelligent machines that we might create. Life generally tends to spread and use up resources, and intelligent life or intelligence generally does so even more deliberately. As space colonization would so vastly increase the stakes at which we are playing, a failure to improve sufficiently alongside all the necessary dimensions – both morally and with regard to overcoming coordination problems or lack of foresight – could result in futures that, even though they may in many cases (different from the AS scenario above!) also contain astronomically many happy individuals, would contain vast quantities of suffering. We can envision numerous conceptual pathways that lead to astronomical amounts of suffering (Sotala & Gloor, 2017), and while each single pathway may seem unlikely to be instantiated – as with most specific predictions about the long-term future – s-risks are disjunctive, and people tend to underestimate the probability of disjunctive events (Dawes & Hastie, 2001). In particular, our historical track record contains all kinds of factors that directly cause or contribute to suffering on large scales:
- Darwinian competition (exemplified by the suffering of wild animals)
- Coordination problems and economic competition (exemplified by suffering caused or exacerbated by income inequality, both locally and globally, and the difficulty of reaching a long-term stable state where Malthusian competition is avoided)
- Hatred of outgroups (exemplified by the Holocaust)
- Indifference (exemplified by the suffering of animals in factory farms)
- Conflict (exemplified by the suffering of a population during/after conquest or siege; sometimes coupled with the promise that surrender will spare the torture of civilians)
- Sadism (exemplified by cases of animal abuse, which may not make up a large source of current-day suffering but could become a bigger issue with cruelty-enabling technologies of the future)
And while one can make a case that there has been a trend for things to become better (see Pinker, 2011), this does not hold in all domains (e.g. not with regard to the number of animals directly harmed in the food industry) and we may, because of filter bubbles for instance, underestimate how bad things still are even in comparatively well-off countries such as the US. Furthermore, it is easy to overestimate the trend for things to have gotten better given that the underlying mechanisms responsible for catastrophic events such as conflict or natural disasters may follow a power law distribution where the vast majority of violent deaths, diseases or famines result from a comparatively small number of particularly devastating incidents. Power law distributions constitute a plausible (though tentative) candidate for modelling the likelihood and severity of suffering risks. If this model is correct, then observations such as that the world did not erupt in the violence of a third world war, or that no dystopian world government has been formed as of late, cannot count as very reassuring, because power law distributions become hard to assess precisely towards the tail-end of the spectrum where the stakes become altogether highest (Newman, 2006).
In order to now illustrate the difference between downside- and upside-focused views, I drew two graphs. To keep things simple, I will limit the example scenarios to cases that either uncontroversially contain more suffering than happiness, or only contain happiness. The BAU scenario from above will serve as reference point. I’m describing it again as reminder below, alongside the other scenarios I will use in the illustration (note that all scenarios are stipulated to last for equally long):
Business as usual (BAU)
Earth remains the only planet in the observable universe (as far as we know) where there is suffering, and things continue as they are. Some people remain in extreme poverty, many people suffer from disease or mental illness, and our psychological makeup limits the amount of time we can remain content with things even if our lives are comparatively fortunate. Factory farms stay open, and most wild animals die before they reach their reproductive age.
Astronomical suffering (AS)
A scenario where space colonization results in an outcome where astronomically many sentient minds exist in conditions that are evaluated as bad by all plausible means of evaluation. To make the scenario more concrete, let us stipulate that 90% of beings in this vast population have lives filled with medium-intensity suffering, and 10% of the population suffers in strong or unbearable intensity. There is little or no happiness in this scenario.
Paradise (small or astronomical; SP/AP)
Things go as well as possible, suffering is abolished, all sentient beings are always happy and even experience heights of well-being that are unachievable with present-day technology. We further distinguish small paradise (SP) from astronomical paradise (AP): while the former stays earth-bound, the latter spans across (maximally) many galaxies, optimized to turn available resources into flourishing lives and all the things people value.
Here is how I envision typical suffering-focused and upside-focused views ranking the above scenarios from “comparatively bad” on the left to “comparatively good” on the right:
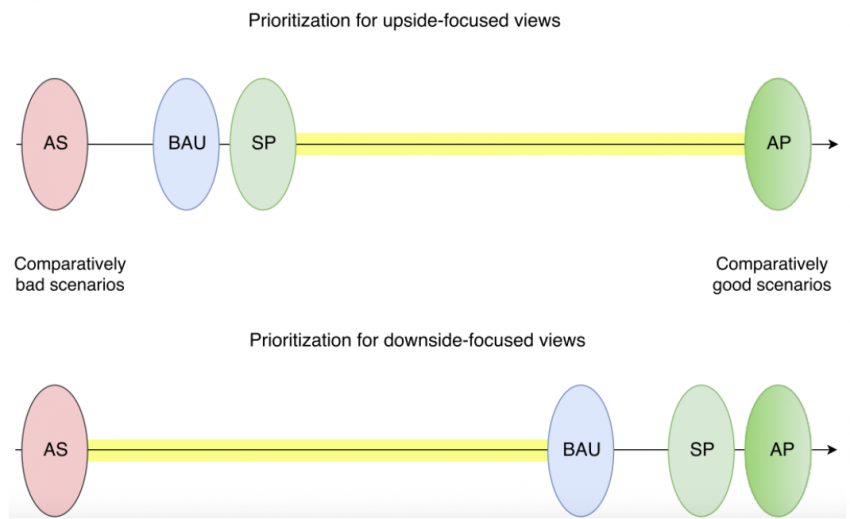
The two graphs represent the relative value we can expect from the classes of future scenarios I described above. The leftmost point of a graph represents not the worst possible outcome, but the worst outcome amongst the future scenarios we are considering. The important thing is not whether a given scenario is more towards the right or left side of the graph, but rather how large the distance is between scenarios. The yellow stretch signifies the highest importance or scope, and interventions that move probability mass across that stretch are either exceptionally good or exceptionally bad, depending on the direction of the movement. (Of course, in practice interventions can also have complex effects that affect multiple variables at once.)
Note that the BAU scenario was chosen mostly for illustration, as it seems pretty unlikely that humans would continue to exist in the current state for extremely long timespans. Similarly, I should qualify that the SP scenario may be unlikely to ever happen in practice because it seems rather unstable: Keeping value drift and Darwinian dynamics under control and preserving a small utopia for millions of years or beyond may require technology that is so advanced that one may as well make the utopia astronomically large – unless there are overriding reasons for favoring the smaller utopia. From any strongly or exclusively downside-focused perspective, the smaller utopia may indeed – factoring out concerns about cooperation – be preferable, because going from SP to AP comes with some risks.9 However, for the purposes of the first graph above, I was stipulating that AP is completely flawless and risk-free.
A “near paradise” or “flawed paradise” mostly filled with happy lives but also with, say, 1% of lives in constant misery, would for upside-focused views rank somewhere close to AP on the far right end of the first graph. By contrast, for downside-focused views on the second graph, “flawed paradise” would stand more or less in the same position as BAU in case the view in question is weakly downside-focused, and decidedly more on the way towards AS on the left in case the view in question is strongly or exclusively downside-focused. Weakly downside-focused views would also have a relatively large gap between SP and AP, reflecting that creating additional happy beings is regarded as morally quite important but not sufficiently important to become the top priority. A view would still count as suffering-focused (at least within the restricted context of our visualization where all scenarios are artificially treated as having the same probability of occurrence) as long as the gap between BAU and AS would remain larger than the gap between BAU/SP and AP.
In practice, we are well-advised to hold very large uncertainty over what the right way is to conceptualize the likelihood and plausibility of such future scenarios. Given this uncertainty, there can be cases where a normative view falls somewhere in-between upside- and downside-focused in our subjective classification. All these things are very hard to predict and other people may be substantially more or substantially less optimistic with regard to the quality of the future. My own estimate is that a more realistic version of AP, one that is allowed to contain some suffering but is characterized by containing near-maximal quantities of happiness or things of positive value, is ~40 times less likely to happen10 than the vast range of scenarios (of which AS is just one particularly bad example) where space colonization leads to outcomes with a lot less happiness. I think scenarios as bad as AS or worse are also very rare, as most scenarios that involve a lot of suffering may also contain some islands of happiness (or even have a sea of happiness and some islands of suffering). See also these posts on why the future is likely to be net good in expectation according to views where creating happiness is similarly important as reducing suffering.
Interestingly, various upside-focused views may differ normatively with respect to how fragile (or not) their concept of positive value is. If utopia is very fragile, but dystopia comes in vastly many forms (related: the Anna Karenina principle), this would imply greater pessimism regarding the value of the average scenario with space colonization, which could push such views closer to becoming downside-focused. On the other hand, some (idiosyncratic) upside-focused views may simply place an overriding weight on the ongoing existence of conscious life, largely independent of how things will go in terms of hedonist welfare.11 Similarly, normatively upside-focused views that count creating happiness as more important than reducing suffering (though presumably very few people would hold such views) would always come out as upside-focused in practice, too, even if we had reason to be highly pessimistic about the future.
To summarize, what the graphs above try to convey is that for the example scenarios listed, downside-focused views are characterized by having the largest gap in relative importance between AS and the other scenarios. By contrast, upside-focused views place by far the most weight on making sure AP happens, and SP would (for many upside-focused views at least) not even count as all that good, comparatively.12
Extinction risk reduction: Unlikely to be positive according to downside-focused views
Some futures, such as ones where most people’s quality of life is hellish, are worse than extinction. Many people with upside-focused views would agree. So the difference between upside- and downside-focused views is not about whether there can be net negative futures, but about how readily a future scenario is ranked as worth bringing about in the face of the suffering it contains or the downside risks that lie on the way from here to there.
If humans went extinct, this would greatly reduce the probability of space colonization and any associated risks (as well as benefits). Without space colonization, there are no s-risks “by action,” no risks from the creation of astronomical suffering where human activity makes things worse than they would otherwise be.13 Perhaps there would remain some s-risks “by omission,” i.e. risks corresponding to a failure to prevent astronomical disvalue. But such risks appear unlikely given the apparent emptiness of the observable universe.14 Because s-risks by action overall appear to be more plausible than s-risks by omission, and because the latter can only be tackled in an (arguably unlikely) scenario where humanity accomplishes the feat of installing compassionate values to robustly control the future, it appears as though downside-focused altruists have more to lose from space colonization than they have to gain.
It is however not obvious whether this implies that efforts to reduce the probability of human extinction indirectly increase suffering risks or downside risks more generally. It very much depends on the way this is done and what other effects are. For instance, there is a large and often underappreciated difference between existential risks from bio- or nuclear technology, and existential risks related to smarter-than-human artificial intelligence (superintelligence; see the next section). While the former set back technological progress, possibly permanently so, the latter drives it all the way up, likely – though maybe not always – culminating in space colonization with the purpose of benefiting whatever goal(s) the superintelligent AI systems are equipped with (Omohundro 2008; Armstrong & Sandberg, 2013). Because space colonization may come with some associated suffering in this way, this means that a failure to reduce existential risks from AI is often also a failure to prevent s-risks from AI misalignment. Therefore, the next section will argue that reducing such AI-related risks is valuable from both upside- and downside-focused perspectives. By contrast, the situation is much less obvious for other existential risks, ones that are not about artificial superintelligence.
Sometimes efforts to reduce these other existential risks also benefits s-risk reduction. For instance, efforts to reduce non-AI-related extinction risks may increase global stability and make particularly bad futures less likely in those circumstances where humanity nevertheless goes on to colonize space. Efforts to reduce extinction risks from e.g. biotechnology or nuclear war in practice also reduce the risk of global catastrophes where a small number of humans survive and where civilization is likely to eventually recover technologically, but perhaps at the cost of a worse geopolitical situation or with worse values, which could then lead to increases in s-risks going into the long-term future. This mitigating effect on s-risk reduction through a more stable future is substantial and positive according to downside-focused value systems, which has to be weighed against the effects of making s-risks from space colonization more likely.
Interestingly, if we care about the total number of sentient minds (and their quality of life) that can at some point be created, then because of some known facts about cosmology,15 any effects that near-extinction catastrophes have on delaying space colonization are largely negligible in the long run when compared to affecting the quality of a future with space colonization – at least unless the delay becomes very long indeed (e.g. millions of years or longer).
What this means is that in order to determine how reducing the probability of extinction from things other than superintelligent AI in expectation affects downside risks, we can approximate the answer by weighing the following two considerations against each other:
- How likely is it that the averted catastrophes merely delay space colonization rather than preventing it completely?
- How much better or worse would a second version of a technologically mature civilization (after a global catastrophe thwarted the first attempt) fare with respect to downside risks?16
The second question involves judging where our current trajectory falls, quality-wise, when compared to the distribution of post-rebuilding scenarios – how much better or worse is our trajectory than a random resetted one? It also requires estimating the effects of post-catastrophe conditions on AI development – e.g., would a longer time until technological maturity (perhaps due to a lack of fossil fuels) cause a more uniform distribution of power, and what does that imply about the probability of arms races? It seems difficult to account for all of these considerations properly. It strikes me as more likely than not that things would be worse after recovery, but because there are so many things to consider,17 I do not feel very confident about this assessment.
This leaves us with the question of how likely a global catastrophe is to merely delay space colonization rather than preventing it. I have not thought about this in much detail, but after having talked to some people (especially at FHI) who have investigated it, I updated that rebuilding after a catastrophe seems quite likely. And while a civilizational collapse would set a precedent and reason to worry the second time around when civilization reaches technological maturity again, it would take an unlikely constellation of collapse factors to get stuck in a loop of recurrent collapse, rather than at some point escaping the setbacks and reaching a stable plateau (Bostrom, 2009), e.g. through space colonization. I would therefore say that large-scale catastrophes related to biorisk or nuclear war are quite likely (~80–90%) to merely delay space colonization in expectation.18 (With more uncertainty being not on the likelihood of recovery, but on whether some outlier-type catastrophes might directly lead to extinction.)
This would still mean that the successful prevention of all biorisk and risks from nuclear war makes space colonization 10-20% more likely. Comparing this estimate to the previous, uncertain estimate about the s-risks profile of a civilization after recovery, it tentatively seems to me that the effect of making cosmic stakes (and therefore downside risks) more likely is not sufficiently balanced by positive effects19 on stability, arms race prevention and civilizational values (factors which would make downside risks less likely). However, this is hard to assess and may change depending on novel insights.
What looks slightly clearer to me is that making rebuilding after a civilizational collapse more likely comes with increased downside risks. If this was the sole effect of an intervention, I would estimate it as overall negative for downside-focused views (factoring out considerations of moral uncertainty or cooperation with other value systems) – because not only would it make it more likely that space will eventually be colonized, but it would also do so in a situation where s-risks might be higher than in the current trajectory we are on.20
However, in practice it seems as though any intervention that makes recovery after a collapse more likely would also have many other effects, some of which might more plausibly be positive according to downside-focused ethics. For instance, an intervention such as developing alternate foods might merely speed up rebuilding after civilizational collapse rather than making it altogether more likely, and so would merely affect whether rebuilding happens from a low base or a high base. One could argue that rebuilding from a higher base is less risky also from a downside-focused perspective, which makes things more complicated to assess. In any case, what seems clear is that none of these interventions look promising for the prevention of downside risks.
We have seen that efforts to reduce extinction risks (exception: AI alignment) are unpromising interventions for downside-focused value systems, and some of the interventions available in that space (especially if they do not simultaneously also improve the quality of the future) may even be negative when evaluated purely from this perspective. This is a counterintuitive conclusion, maybe so much so that many people would rather choose to adopt moral positions where it does not follow. In this context, it is important to point out that valuing humanity not going extinct is definitely compatible with a high degree of priority for reducing suffering or disvalue. I view morality as including both considerations about duties towards other people (inspired by social contract theories or game theoretic reciprocity) as well as considerations of (unconditional) care or altruism. If both types of moral considerations are to be weighted similarly, then while the “care” dimension could e.g. be downside-focused, the other dimension, which is concerned with respecting and cooperating with other people’s life goals, would not be – at least not under the assumption that the future will be good enough that people want it to go on – and would certainly not welcome extinction.
Another way to bring together both downside-focused concerns and a concern for humanity not going extinct would be through a morality that evaluates states of affairs holistically, as opposed to using an additive combination for individual welfare and a global evaluation of extinction versus no extinction. Under such a model, one would have a bounded value function for the state of the world as a whole, so that a long history with great heights of discovery or continuity could improve the evaluation of the whole history, as would properties like highly favorable densities of good things versus bad things.
Altogether, because more people seem to come to hold upside-focused or at least strongly extinction-averse values after grappling with the arguments in population ethics, reducing extinction risk can be part of a fair compromise even though it is an unpromising and possibly negative intervention from a downside-focused perspective. After all, the reduction of extinction risks is particularly important from both an upside-focused perspective and from the perspective of (many) people’s self-, family- or community-oriented moral intuitions – because of the short-term death risks it involves.21 Because it is difficult to identify interventions that are robustly positive and highly impactful according to downside-focused value systems (as the length of this post and the uncertain conclusions indicate), it is however not a trivial issue that many commonly recommended interventions are unlikely to be positive according to these value systems. To the extent that downside-focused value systems are regarded as a plausible and frequently arrived at class of views, considerations from moral uncertainty and moral cooperation (see the last section) recommend some degree of offsetting expected harms through targeted efforts to reduce s-risks, e.g. in the space of AI risk (next section). Analogously, downside-focused altruists should not increase extinction risks and instead focus on more cooperative ways to reduce future disvalue.
AI alignment: (Probably) positive for downside-focused views; high variance
Smarter-than-human artificial intelligence will likely be particularly important for how the long-term future plays out. There is a good chance that the goals of superintelligent AI would be much more stable than the values of individual humans or those enshrined in any constitution or charter, and superintelligent AIs would – at least with considerable likelihood – remain in control of the future not only for centuries, but for millions or even billions of years to come. In this section, I will sketch some crucial considerations for how work in AI alignment is to be evaluated from a downside-focused perspective.
First, let’s consider a scenario with unaligned superintelligent AI systems, where the future is shaped according to goals that have nothing to do with what humans value. Because resource accumulation is instrumentally useful to most consequentialist goals, it is likely to be pursued by a superintelligent AI no matter its precise goals. Taken to its conclusion, the acquisition of ever more resources culminates in space colonization where accessible raw material is used to power and construct supercomputers and other structures that could help in the pursuit of a consequentialist goal. Even though random or “accidental” goals are unlikely to intrinsically value the creation of sentient minds, they may lead to the instantiation of sentient minds for instrumental reasons. In the absence of explicit concern for suffering reflected in the goals of a superintelligent AI system, that system would instantiate suffering minds for even the slightest benefit to its objectives. Suffering may be related to powerful ways of learning (Daswani & Leike, 2015), and an AI indifferent to suffering might build vast quantities of sentient subroutines, such as robot overseers, robot scientists or subagents inside larger AI control structures. Another danger is that, either during the struggle over control over the future in a multipolar AI takeoff scenario, or perhaps in the distant future should superintelligent AIs ever encounter other civilizations, conflict or extortion could result in large amounts of disvalue. Finally, superintelligent AI systems might create vastly many sentient minds, including very many suffering ones, by running simulations of evolutionary history for research purposes (“mindcrime;” Bostrom, 2014, pp. 125-26). (Or for other purposes; if humans had the power to run alternative histories in large and fine-grained simulations, probably we could think of all kinds of reasons for doing it.) Whether such history simulations would be fine-grained enough to contain sentient minds, or whether simulations on a digital medium can even qualify as sentient, are difficult and controversial questions. It should be noted however that the stakes are high enough such that even comparatively small credences such as 5% or lower would already go a long way in terms of the implied expected value for the overall severity of s-risks from artificial sentience (see also footnote 7).
While the earliest discussions about the risks from artificial superintelligence have focused primarily on scenarios where a single goal and control structure decides the future (singleton), we should also remain open for scenarios that do not fit this conceptualization completely. Perhaps what happens instead could be several goals either competing or acting in concert with each other, like an alien economy that drifted further and further away from originally having served the goals of its human creators.22 Alternatively, perhaps goal preservation becomes more difficult the more capable AI systems become, in which case the future might be controlled by unstable goal functions taking turns over the steering wheel (see “daemons all the way down”). These scenarios where no proper singleton emerges may perhaps be especially likely to contain large numbers of sentient subroutines. This is because navigating a landscape with other highly intelligent agents requires the ability to continuously model other actors and to react to changing circumstances under time pressure – all of which are things that are plausibly relevant for the development of sentience.
In any case, we cannot expect with confidence that a future controlled by non-compassionate goals will be a future that neither contains happiness nor suffering. In expectation, such futures are instead likely to contain vast amounts of both happiness and suffering, simply because these futures would contain astronomical amounts of goal-directed activity in general.
Successful AI alignment could prevent most of the suffering that would happen in an AI-controlled future, as a superintelligence with compassionate goals would be willing to make tradeoffs that substantially reduce the amount of suffering contained in any of its instrumentally useful computations. While a “compassionate” AI (compassionate in the sense that its goal includes concern for suffering, though not necessarily in the sense of experiencing emotions we associate with compassion) might still pursue history simulations or make use of potentially sentient subroutines, it would be much more conservative when it comes to risks of creating suffering on large scales. This means that it would e.g. contemplate using fewer or slightly less fine-grained simulations, slightly less efficient robot architectures (and ones that are particularly happy most of the time), and so on. This line of reasoning suggests that AI alignment might be highly positive according to downside-focused value systems because it averts s-risks related to instrumentally useful computations.
However, work in AI alignment not only makes it more likely that fully aligned AI is created and everything goes perfectly well, but it also affects the distribution of alignment failure modes. In particular, progress in AI alignment could make it more likely that failure modes shift from “very far away from perfect in conceptual space” to “close but slightly off the target.” There are some reasons why such near misses might sometimes end particularly badly.
What could loosely be classified as a near miss is that certain work in AI alignment makes it more likely that AIs would share whichever values their creators want to install, but the creators could be unethical or (meta-)philosophically and strategically incompetent.
For instance, if those in power of the future came to follow some kind of ideology that is uncompassionate or even hateful of certain out-groups, or favor a distorted version of libertarianism where every person, including a few sadists, would be granted an astronomical quantity of future resources to use it at their disposal, the resulting future could be a bad one according to downside-focused ethics.
A related and perhaps more plausible danger is that we might prematurely lock in a definition of suffering and happiness into an AI’s goals that neglects sources of suffering we would come to care about after deeper reflection, such as not caring about the mind states of insect-like digital minds (which may or may not be reasonable). A superintelligence with a random goal would also be indifferent with regard to these sources of suffering, but because humans value the creation of sentience, or at least value processes related to agency (which tend to correlate with sentience), the likelihood is greater that a superintelligence with aligned values would create unnoticed or uncared for sources of suffering. Possible such sources include the suffering of non-human animals in nature simulations performed for aesthetic reasons, or characters in sophisticated virtual reality games.
A further danger is that, if our strategic or technical understanding is too poor, we might fail to specify a recipe for getting human values right and end up with perverse instantiation (Bostrom, 2014) or a failure mode where the reward function ends up flawed. This could happen e.g. to cases where an AI system starts to act in unpredictable but optimized ways due to conducting searches far outside its training distribution.23 Probably most mistakes at that stage would result in about as much suffering as in the typical scenario where AI is unaligned and has (for all practical purposes) random goals. However, one possibility is that alignment failures surrounding utopia-directed goals have a higher chance of leading to dystopia than alignment failures around random goals. For instance, a failure to fully understand the goal 'make maximally many happy minds' could lead to a dystopia where maximally many minds are created in conditions that do not reliably produce happiness, and may even lead to suffering in some of the instances, or some of the time. This is an area for future research.
A final possible outcome in the theme of “almost getting everything right” is if one where we are able to successfully install human values into an AI, only to have the resulting AI compete with other, unaligned AIs for control of the future and be threatened with things that are bad according to human values, in the expectation that the human-aligned AI would then forfeit its resources and give up in the competition over controlling the future.
Trying to summarize the above considerations, I drew a (sketchy) map with some major categories of s-risks related to space colonization. It highlights that artificial intelligence can be regarded as a cause or cure for s-risks (Sotala & Gloor, 2017). That is, if superintelligent AI is successfully aligned, s-risks stemming from indifference to suffering are prevented and a maximally valuable future is instantiated (green). However, the danger of near misses (red) makes it non-obvious whether efforts in AI alignment reduce downside risks overall, as the worst near misses may e.g. contain more suffering than the average s-risk scenario.

Note that no one should quote the above map out of context and call it “The likely future” or something like that, because some of the scenarios I listed may be highly improbable and because the whole map is drawn with a focus on things that could go wrong. If we wanted a map that also tracked outcomes with astronomical amounts of happiness, there would in addition be many nodes for things like “happy subroutines,” “mindcrime-opposite,” “superhappiness-enabling technologies,” or “unaligned AI trades with aligned AI and does good things after all.” There can be futures in which several s-risk scenarios come to pass at the same time, as well as futures that contain s-risk scenarios but also a lot of happiness (this seems pretty likely).
To elaborate more on the categories in the map above: Pre-AGI civilization (blue) is the stage we are at now. Grey boxes refer to various steps or conditions that could be met, from which s-risks (orange and red), extinction (yellow) or utopia (green) may follow. The map is crude and not exhaustive. For instance “No AI Singleton” is a somewhat unnatural category into which I threw both scenarios where AI systems play a crucial role and scenarios where they do not. That is, the category contains futures where space colonization is orchestrated by humans or some biological successor species without AI systems that are smarter than humans, futures where AI systems are used as tools or oracles for assistance, and futures where humans are out of the loop but no proper singleton emerges in the competition between different AI systems.
Red boxes are s-risks that may be intertwined with efforts in AI alignment (though not by logical necessity): If one is careless, work in AI alignment may exacerbate these s-risks rather than alleviate them. While dystopia from extortion would never be the result of the activities of an aligned AI, it takes an AI with aligned values, e.g. alongside the unaligned AI in a multipolar scenario or alien AI encountered during space colonization, to even provoke such a threat (hence the dotted line linking this outcome to “value loading success”). I coined the term “aligned-ish AI” to refer to the class of outcomes that efforts in AI alignment shifts probability mass to. This class includes both very good outcomes (intentional) and neutral or very bad outcomes (accidental). Flawed realization – which stands for futures where flaws in alignment prevent most of the value or even create disvalue – is split into two subcategories in order to highlight that the vast majority of such outcomes likely contains no more suffering than the typical outcome with unaligned AI, but that things going wrong in a particularly unfortunate way could result in exceptionally bad futures. For views that care similarly strongly about achieving utopia than preventing very bad futures, this tradeoff seems most likely net positive, whereas from a downside-focused perspective, this consideration makes it less clear whether efforts in AI alignment are overall worth the risks.
Fortunately, not all work in AI alignment faces the same tradeoffs. Many approaches may be directed specifically against avoiding certain failure modes, which is extremely positive and impactful for downside-focused perspectives. Worst-case AI safety is the idea that downside-focused value systems recommend pushing differentially the approaches that appear safest with respect to particularly bad failure modes. Given that many approaches towards AI alignment are still at a very early stage, it may be hard to tell which components to AI alignment are likely to benefit downside-focused perspectives the most. Nevertheless, I think we can already make some informed guesses, and our understanding will improve with time.
For instance, approaches that make AI systems corrigible (see here and here) would extend the window of time during which we can spot flaws and prevent outcomes with flawed realization. Similarly, approval-directed approaches to AI alignment, where alignment is achieved by simulating what a human overseer would decide if they were to think about the situation for a very long time, would go further towards avoiding bad decisions than approaches with immediate, unamplified feedback from human overseers. And rather than trying to solve AI alignment in one swoop, a promising and particularly “s-risk-proof” strategy might be to first build a low-impact AI systems that increases global stability and prevent arms races without actually representing fully specified human values. This would give everyone more time to think about how to proceed and avoid failure modes where human values are (partially) inverted.
In general, especially from a downside-focused perspective, it strikes me as very important that early and possibly flawed or incomplete AI designs should not yet attempt to fully specify human values. Eliezer Yudkowsky recently expressed the same point in this Arbital post on the worst failure modes in AI alignment.
Finally, what could also be highly effective for reducing downside risks, as well as being important for many other reasons, is some of the foundational work in bargaining and decision theory for AI systems, done at e.g. the Machine Intelligence Research Institute, which could help us understand how to build AI systems that reliably steer things towards outcomes that are always positive-sum.
I have a general intuition that, at least as long as the AI safety community does not face a strong pressure from (perceived) short timelines where the differences between downside-focused and upside-focused views may become more pronounced, there is likely to be a lot of overlap in terms of the most promising approaches focused on achieving the highest probability of success (utopia creation) and approaches that are particularly robust against failing in the most regretful ways (dystopia prevention). Heuristics like ‘Make AI systems corrigible,’ ‘Buy more time to think,’ or ‘If there is time, figure out some foundational issues to spot unanticipated failure modes’ all seem as though they would more likely be useful from both perspectives, especially when all good guidelines are followed without exception. I also expect that reasonably many people working in AI alignment will gravitate towards approaches that are robust in all these respects, because making your approach multi-layered and foolproof simply is a smart strategy when the problem in question is unfamiliar and highly complex. Furthermore, I anticipate that more people will come to think more explicitly about the tradeoffs between the downside risks from near misses and utopian futures, and some of them might put deliberate efforts into finding AI alignment methods or alignment components that fail gracefully and thereby make downside risks less likely (worst-case AI safety), either because of intrinsic concern or for reasons of cooperation with downside-focused altruists.24 All of these things make me optimistic about AI alignment as a cause area being roughly neutral or slightly positive when done with little focus on downside-focused considerations, and strongly positive when pursued with with strong concern for avoiding particularly bad outcomes.
I also want to mention that I think the entire field of AI policy and strategy strikes me as particularly positive for downside-focused value systems. Making sure that AI development is done carefully and cooperatively, without the threat of arms races leading to ill-considered, rushed approaches, seems like it would be exceptionally positive from all perspectives, and so I recommend that people who fulfill the requirements for such work should prioritize it very highly.
Moral uncertainty and cooperation
Population ethics, which is the area in philosophy most relevant for deciding between upside- and downside-focused positions, is a notoriously contested topic. Many people who have thought about it a great deal believe that the appropriate epistemic state with regard to a solution to population ethics is one of substantial moral uncertainty or of valuing further reflection on the topic. Let us suppose therefore that, rather than being convinced that some form of suffering-focused ethics or downside-focused morality is the stance we want to take, we consider it a plausible stance we very well might want to take, alongside other positions that remain in contention.
Analogous to situations with high empirical uncertainty, there are two steps to consider for deciding under moral uncertainty:
- (1) Estimate the value of information from attempts to reduce uncertainty, and the time costs of such attempts
and compare that with
- (2) the uncertainty-adjusted value from pursuing those interventions that are best from our current epistemic perspective
With regard to (1), we can reduce our moral uncertainty on two fronts. The obvious one is population ethics: We can learn more about the arguments for different positions, come up with new arguments and positions, and assess them critically. The second front concerns meta-level questions about the nature of ethics itself, what our uncertainty is exactly about, and in which ways more reflection or a sophisticated reflection procedure with the help of future technology would change our thinking. While some people believe that it is futile to even try reaching confident conclusions in the epistemic position we are in currently, one could also arrive at a view where we simply have to get started at some point, or else we risk getting stuck in a state of underdetermination and judgment calls all the way down.25
If we conclude that the value of information is insufficiently high to justify more reflection, then we can turn towards getting value from working on direct interventions (2) informed by those moral perspectives we have substantial credence in. For instance, a portfolio for effective altruists in the light of total uncertainty over downside- vs. upside-focused views (which may not be an accurate representation of the EA landscape currently, where upside-focused views appear to be in the majority) would include many interventions that are valuable from both perspectives, and few interventions where there is a large mismatch such that one side is harmed without the other side attaining a much greater benefit. Candidate interventions where the overlap between downside-focused and upside-focused views is high include AI strategy and AI safety (perhaps with a careful focus on the avoidance of particularly bad failure modes), as well as growing healthy communities around these interventions. Many other things might be positive from both perspectives too, such as (to name only a few) efforts to increase international cooperation, raising awareness and concern for for the suffering of non-human sentient minds, or improving institutional decision-making.
It is sometimes acceptable or even rationally mandated to do something that is negative according to some plausible moral views, provided that the benefits accorded to other views are sufficiently large. Ideally, one would consider all of these considerations and integrate the available information appropriately with some decision procedure for acting under moral uncertainty, such as one that includes variance voting (MacAskill, 2014, chpt. 3) and an imagined moral parliament.26 For instance, if someone leaned more towards upside-focused views, or had reasons to believe that the low-hanging fruit in the field of non-AI extinction risk reduction are exceptionally important from the perspective of these views (and unlikely to damage downside-focused views more than they can be benefitted elsewhere), or gives a lot of weight to the argument from option value (see the next paragraph), then these interventions should be added at high priority to the portfolio as well.
Some people have argued that even (very) small credences in upside-focused views, such as 1-20% for instance, would in itself already speak in favor of making extinction risk reduction a top priority because making sure there will still be decision-makers in the future provides high option value. I think this gives by far too much weight to the argument from option value. Option value does play a role, but not nearly as strong a role as it is sometimes made out to be. To elaborate, let’s look at the argument in more detail: The naive argument from option value says, roughly, that our descendants will be in a much better position to decide than we are, and if suffering-focused ethics or some other downside-focused view is indeed the outcome of their moral deliberations, they can then decide to not colonize space, or only do so in an extremely careful and controlled way. If this picture is correct, there is almost nothing to lose and a lot to gain from making sure that our descendants get to decide how to proceed.
I think this argument to a large extent misses the point, but seeing that even some well-informed effective altruists seem to believe that it is very strong led me realize that I should write a post explaining the landscape of cause prioritization for downside-focused value systems. The problem with the naive argument from option value is that the decision algorithm that is implicitly being recommended in the argument, namely focusing on extinction risk reduction and leaving moral philosophy (and s-risk reduction in case the outcome is a downside-focused morality) to future generations, makes sure that people follow the implications of downside-focused morality in precisely the one instance where it is least needed, and never otherwise. If the future is going to be controlled by philosophically sophisticated altruists who are also modest and willing to change course given new insights, then most bad futures will already have been averted in that scenario. An outcome where we get long and careful reflection without downsides is far from the only possible outcome. In fact, it does not even seem to me to be the most likely outcome (although others may disagree). No one is most worried about a scenario where epistemically careful thinkers with their heart in the right place control the future; the discussion is instead about whether the probability that things will accidentally go off the rails warrants extra-careful attention. (And it is not as though it looks like we are particularly on the rails currently either.) Reducing non-AI extinction risk does not preserve much option value for downside-focused value systems because most of the expected future suffering probably comes not from scenarios where people deliberately implement a solution they think is best after years of careful reflection, but instead from cases where things unexpectedly pass a point of no return and compassionate forces do not get to have control over the future. Downside risks by action likely loom larger than downside risks by omission, and we are plausibly in a better position to reduce the most pressing downside risks now than later. (In part because “later” may be too late.)
This suggests that if one is uncertain between upside- and downside-focused views, as opposed to being uncertain between all kinds of things except downside-focused views, the argument from option value is much weaker than it is often made out to be. Having said that, non-naively, option value still does upshift the importance of reducing extinction risks quite a bit – just not by an overwhelming degree. In particular, arguments for the importance of option value that do carry force are for instance:
- There is still some downside risk to reduce after long reflection
- Our descendants will know more about the world, and crucial considerations in e.g. infinite ethics or anthropics could change the way we think about downside risks (in that we might for instance realize that downside risks by omission loom larger than we thought)
- One’s adoption of (e.g.) upside-focused views after long reflection may correlate favorably with the expected amount of value or disvalue in the future (meaning: conditional on many people eventually adopting upside-focused views, the future is more valuable according to upside-focused views than it appears during an earlier state of uncertainty)
The discussion about the benefits from option value is interesting and important, and a lot more could be said on both sides. I think it is safe to say that the non-naive case for option value is not strong enough to make extinction risk reduction a top priority given only small credences in upside-focused views, but it does start to become a highly relevant consideration once the credences become reasonably large. Having said that, one can also make a case that improving the quality of the future (more happiness/value and less suffering/disvalue) conditional on humanity not going extinct is probably going to be at least as important for upside-focused views and is more robust under population ethical uncertainty – which speaks particularly in favor of highly prioritizing existential risk reduction through AI policy and AI alignment.
We saw that integrating population-ethical uncertainty means that one should often act to benefit both upside- and downside-focused value systems – at least in case such uncertainty applies in one’s own case and epistemic situation. Moral cooperation presents an even stronger and more universally applicable reason to pursue a portfolio of interventions that is altogether positive according both perspectives. The case for moral cooperation is very broad and convincing, as it ranges from commonsensical heuristics to theory-backed principles found in Kantian morality or throughout Parfit’s work, as well as in the literature on decision theory.27 It implies that one should give extra weight to interventions that are positive for value systems different from one’s own, and subtract some weight from interventions that are negative according to other value systems – all to the extent in which the value systems in question are endorsed prominently or endorsed by potential allies.28
Considerations from moral cooperation may even make moral reflection obsolete on the level of individuals: Suppose we knew that people tended to gravitate towards a small number of attractor states in population ethics, and that once a person tentatively settles on a position, they are very unlikely to change their mind. Rather than everyone going through this process individually, people could collectively adopt a decision rule where they value the outcome of a hypothetical process of moral reflection. They would then work on interventions that are beneficial for all the commonly endorsed positions, weighted by the probability that people would adopt them if they were to go through long-winded moral reflection. Such a decision rule would save everyone time that could be spent on direct work rather than philosophizing, but perhaps more importantly, it would also make it much easier for people to benefit different value systems cooperatively. After all, when one is genuinely uncertain about values, there is no incentive to attain uncooperative benefits for one’s own value system.
So while I think the position that valuing reflection is always the epistemically prudent thing to do rests on dubious assumptions (because of the argument from option value being weak, as well as the reasons alluded to in footnote 24), I think there is an intriguing argument that a norm for valuing reflection is actually best from a moral cooperation perspective – provided that everyone is aware of what the different views on population ethics imply for cause prioritization, and that we have a roughly accurate sense of which attractor states people’s moral reflection would seek out.
Even if everyone went on to primarily focus on interventions that are favored by their own value system or their best guess morality, small steps into the direction of cooperatively taking other perspectives into account can already create a lot of additional value for all parties. To this end, everyone benefits from trying to better understand and account for the cause prioritization implied by different value systems.
Acknowledgements
This piece benefitted from comments by Tobias Baumann, David Althaus, Denis Drescher, Jesse Clifton, Max Daniel, Caspar Oesterheld, Johannes Treutlein, Brian Tomasik, Tobias Pulver, Simon Knutsson, Kaj Sotala (who also allowed me to use a map on s-risks he made and adapt it for my purposes in the section on AI) and Jonas Vollmer. The section on extinction risks benefitted from inputs by Owen Cotton-Barratt, and I am also thankful for valuable comments and critical inputs in a second round of feedback by Jan Brauner, Gregory Lewis and Carl Shulman.
References
Armstrong, S. & Sandberg, A. (2013). Eternity in Six Hours: Intergalactic spreading of intelligent life and sharpening the Fermi paradox. Ars Acta 89:1-13.
Bostrom, N. (2003). Astronomical Waste: The Opportunity Cost of Delayed Technological Development. Utilitas 15(3):308-314.
Bostrom, N. (2014). Superintelligence: Paths, Danger, Strategies. Oxford: Oxford University Press.
Daswani, M. & Leike, J. (2015). A Definition of Happiness for Reinforcement Learning Agents. arXiv:1505.04497.
Greaves, H. (2017). Population axiology. Philosophy Compass, 12:e12442. doi.org/10.1111/phc3.12442.
Hastie, R., & Dawes, R. (2001). Rational choice in an uncertain world: The psychology of judgment and decision making. Thousand Oaks: Sage Publications.
MacAskill, W. (2014). Normative Uncertainty. PhD diss., St Anne’s College, University of Oxford.
Newman, E. (2006). Power laws, Pareto distributions and Zipf’s law. arXiv:cond-mat/0412004.
Omohundro, S. (2008). The Basic AI Drives. In P. Wang, B. Goertzel, and S. Franklin (eds.). Proceedings of the First AGI Conference, 171, Frontiers in Artificial Intelligence and Applications. Amsterdam: IOS Press.
Parfit, D. (2011). On What Matters. Oxford: Oxford University Press.
Pinker, S. (2011). The Better Angels of our Nature. New York, NY: Viking.
Sotala, K. & Gloor, L. (2017). Superintelligence as a Cause or Cure for Risks of Astronomical Suffering. Informatica 41(4):389–400.
Endnotes
- Speaking of “bad things” or “good things” has the potential to be misleading, as one might think of cases such as “It is good to prevent bad things” or “It is bad if good things are prevented.” To be clear, what I mean by “bad things” are states of affairs that are in themselves disvaluable, as opposed to states of affairs that are disvaluable only in terms of wasted opportunity costs. Analogously, by “good things” I mean states of affairs that are in themselves worth bringing about (potentially at a cost) rather than just states of affairs that fail to be bad. (back)
- It is a bit more complicated: If one thought that for existing people, there is a vast amount of value to be achieved by ensuring that people live very long and very happy lives, then even views that focus primarily on the well-being of currently existing people or people who will exist regardless of one’s actions may come out as upside-focused. For this to be the case, one would need to have reason to believe that these vast upsides are realistically within reach, that they are normatively sufficiently important when compared with downside risks for the people in question (such as people ending up with long, unhappy lives or extremely unhappy lives), and that these downside risks are sufficiently unlikely (or intractable) empirically to count as the more pressing priority when compared to the upside opportunities at hand.
It is worth noting that a lot of people, when asked e.g. about their goals in life, do not state it as a priority or go to great lengths to live for extremely long, or to experience levels of happiness that are not sustainably possible with current technology. This may serve as a counterargument against this sort of upside-focused position. On the other hand, advocates of that position could argue that people may simply not believe that such scenarios are realistic, and that e.g. some people's longing to go to heaven does actually speak in favor of there being a strong desire for ensuring an exceptionally good, exceptionally long personal future. (back) - I estimate that a view is sufficiently “negative-leaning” to qualify as downside-focused if it says that reducing extreme suffering is much more important (say 100 times or maybe 1,000 times more important) than creating optimized happiness. For normative views with lower exchange rates between extreme suffering and optimal happiness (or generally positive value), prioritization becomes less clear and will often depend on additional specifics of the view in question. There does not appear to be a uniquely correct way to measure happiness and suffering, so talk about it being x times more important to prevent suffering than to create happiness always has to be accompanied with instructions for what exactly is being compared. Because of the possibility that advanced future civilizations may be able to efficiently instantiate mind states that are much more (dis)valuable than the highs and lows of our biology, what seems particularly relevant for estimating the value of the long-term future is the way one compares maximally good happiness and maximally bad suffering. Because presumably we have experienced neither one extreme nor the other, it may be difficult to form a strong opinion on this question, which arguably gives us grounds for substantial moral uncertainty. One thing that seems to be the case is that a lot of people – though not everyone – would introspectively agree that suffering is a lot stronger than happiness at least within the limits of our biology. However, one can draw different interpretations as to why this is the case. Some people believe that this difference would become a lot less pronounced if all possible states of mind could be accessed efficiently with the help of advanced technology. Evolutionary arguments lend some support to this position: It was plausibly more important for natural selection to prevent organisms from artificially maxing out their feelings of positive reward (wireheading) than to prevent organisms from being able to be max out their negative rewards (self-torture). This line of reasoning suggests that us observing that it is rare and very difficult in practice – given our biology – to experience extremely positive states of mind (especially for prolonged periods of time) should not give us a lot of reason to think that such states are elusive in theory. On the other hand, another plausible interpretation of the asymmetry we perceive between suffering and happiness (as we can experience and envision them) would be one that points to an underlying difference in the nature of the two, one that won’t go away even with the help of advanced technology. Proponents of this second interpretation believe that no matter how optimized states of happiness may become in the future, creating happiness will always lack the kind of moral urgency that comes with avoiding extreme suffering. (back)
- Note that prioritarianism or egalitarianism are not upside-focused views even though they may share the similarity with classical hedonistic utilitarianism that they accept versions of the repugnant conclusion. There can be downside-focused views which accept the repugnant conclusion. As soon as lives of negative welfare are at stake, prioritarianism and welfare-based egalitarianism accord especially high moral importance towards preventing these lives, which most likely makes the views downside-focused. (The bent towards giving priority to those worse off would have to be rather mild in order to not come out as downside-focused in practice, especially since one of the reasons people are drawn to these views in the first place might be that they incorporate downside-focused moral intuitions.) (back)
- Person-affecting restrictions are generally considered unpromising as a solution to population ethics. For instance, versions of person-affecting views that evaluate it as neutral to add well-off beings to the world, yet bad to add beings whose welfare is below zero, suffer from what Hilary Greaves (2017) has called a ““remarkabl[e] difficult[y] to formulate any remotely acceptable axiology that captures this idea of ‘neutrality.’” Versions of person-affecting views that evaluate it as negative to add lives to the world with even just a little suffering (e.g. Benatar’s anti-natalism) do not have this problem, but they appear counterintuitive to most people because of how strongly they count such suffering in otherwise well-off lives. (back)
- Within the set of interventions that plausibly have a large positive impact on the long-term future, it is also important to consider one’s comparative advantages. Talent, expertise and motivation for a particular type of work can have a vast effect on the quality of one’s output and can make up for effectiveness differences of one or two orders of magnitude. (back)
- Computationally inefficient in the sense that, with advanced computer technology, one could speed up what functionally goes on in biological brains by a vast factor and create large numbers of copies of such brain emulations on a computer substrate – see for instance this report or Robin Hanson’s The Age of Em. One premise that strongly bears on the likelihood of scenarios where the future contains astronomical quantities of suffering is whether artificial sentience, sentience implemented on computer substrates, is possible. Because most philosophers of mind believe that digital sentience is possible, only having very small credences (say 5% or smaller) in this proposition is unlikely to be epistemically warranted. Moreover, even if digital sentience was impossible, another route to astronomical future suffering is that whatever substrates can produce consciousness would be used/recruited for instrumental purposes. I have also written about this issue here. (back)
- Note that it may turn out that the amount of suffering that we can influence is dwarfed by suffering that we can’t influence. By “expected future suffering” we mean “expected action-relevant suffering in the future”. (back)
- And some people might think that SP, under some speculative assumptions on the philosophy of mind and how one morally values different computations, may contain suffering that is tied up with the paradise requirements and therefore hard to avoid. (back)
- My inside view says they are two orders of magnitude less likely, but I am trying to account for some people being more optimistic. My pessimism derives from there being so many more macroscopically distinct futures that qualify as AS rather than AP, and while I do think AP represents a strong attractor, my intuition is that Molochian forces are difficult to overcome. See also Brian Tomasik's discussion of utopia here. Evidence that might contribute towards making me revise my estimate (up to e.g. 10% likelihood of some kind of utopia given space colonization) would be things such as:
1) A country implementing a scheme to redistribute wealth in a way that eliminates poverty or otherwise generates large welfare benefits without really bad side-effects (including side-effects in other countries).
2) Technologically leading countries achieving a vastly consequential agreement regarding climate change or international coordination with respect to AI development.
3) Demographic trends suggesting a stable decrease in fertility rates for total population prognoses down to sustainability levels or below (especially if stable without highly negative side-effects on a long-term perspective of centuries and beyond).
4) Many countries completely outlawing factory farming in the next couple of decades, especially if non-economic reasons play a major role.
5) Any major, research-relevant jurisdiction outlawing or very tightly regulating the use of certain AI algorithms for fear of needlessly creating sentient minds.
6) Breakthroughs in AI alignment research that make most AI safety researchers (including groups with a track record of being on the more pessimistic side) substantially more optimistic about the future than they currently are. (back) - Some people would say that as long as a being prefers existence over non-existence (and if they would not, there is usually the option of suicide), their existence cannot be net negative even if it contained a lot more suffering than happiness. I would counter that, while I see a strong case from cooperation and respecting someone’s goals for not terminating the existence of a being who wants to continue to go on existing, this is not the same as saying that the being’s existence, assuming it contains only suffering, adds value independently of the being's drives or goals. Goals may not be about only one’s own welfare – they can also include all kinds of objectives, such as living a meaningful life or caring about personal achievements or the state of the world. After all, one would think that Darwinian forces would be unlikely to select for the kind of goals or evaluation mechanisms that easily evaluate one’s life as all things considered not worth living. So rather than e.g. only taking moment-by-moment indicators of one’s experienced well-being, people’s life satisfaction judgment may include many additional, generally life-supporting components that derive from our relation to others and to the world. Correspondingly, not committing suicide is insufficient evidence that, from a purely well-being-oriented perspective, someone’s life is being – even just subjectively – evaluated as net valuable. (If alongside suicide, there was also the option to take a magic pill that turned people into p-zombies, how many people would take it?) We can also think of it this way: If a preference for continued life or no-longer-existence was enough to establish that starting a life is neutral or positive, then someone could engineer artificial beings that always prefer consciousness over non-consciousness, even if they experienced nothing but agony for every second of their existence. It personally strikes me as unacceptable to regard this situation as anything but very bad, but intuitions may differ. (back)
- Technically, one could hold an upside-focused ethical view where SP is similarly good as AP. But this raises the question whether one would have the same intuition for a small dystopia versus a large dystopia. If the large dystopia is orders of magnitude worse than the small dystopia, yet the scope of a potential paradise runs into diminishing returns, then the view in question is either fully downside-focused if the large dystopia is stipulated to be much worse than SP is good, or implausibly indifferent towards downside risks in case SP is labelled as a lot better than a much larger dystopia. Perhaps one could construct a holistic view that is exactly in-between downside- and upside-focused, based on the stipulation that half of one’s moral caring capacity goes into utopia creation and the other half into suffering prevention. This could in practice be equivalent to using a moral parliament approach to moral uncertainty while placing 50% credence on each view. (back)
- One exception is that in theory, one could have a civilization that remains on earth yet uses up as much energy and resources as physically available to instantiate digital sentience at “astronomical” scales on supercomputers built on earth. Of course, the stakes in this scenario are still dwarfed by a scenario where the same thing happens around every star in the accessible universe, but it would still constitute an s-risk in the sense that, if some of these supercomputers run a lot of sentient minds and some of them would suffer, the total amount of suffering could quickly become larger than all the sentience that had existed in life’s history up to that point. (back)
- Though one plausible example might be if a value-aligned superintelligent AI could trade with AIs in other parts of the universe and bargain for suffering reduction. (back)
- From Bostrom’s Astronomical Waste (2003) paper:
“Because the lifespan of galaxies is measured in billions of years, whereas the time-scale of any delays that we could realistically affect would rather be measured in years or decades, the consideration of risk trumps the consideration of opportunity cost. For example, a single percentage point of reduction of existential risks would be worth (from a utilitarian expected utility point-of-view) a delay of over 10 million years.” (back) - For the purposes of this post, I am primarily evaluating the question from the perspective of minimizing s-risks. Of course, when one evaluates the same question according to other desiderata, it turns out that most plausible moral views very strongly favor the current trajectory. Any view that places overriding importance on avoiding involuntary deaths for currently-existing people automatically evaluates the current trajectory as better, because the collapse of civilization would bring an end to any hopes of delaying people’s deaths with the help of advanced technology. Generally, a central consideration here is also that the more one values parochial features of our civilization, such as the survival of popular taste in art, people remembering and revering Shakespeare, or the continued existence of pizza as a food item, etc., the more obvious it becomes that the current trajectory would be better than a civilizational reset scenario. (back)
- Further things to consider include that a civilization recovering with depleted fossil fuels would plausibly tend to be poorer for any given level of technology compared to our historical record. What would this mean for values? By the time they caught up with us in energy production, might they also have been civilized for longer? This could add sophistication in some ways but also increase societal conformity, which could be both good or bad. (back)
- This estimate may appear surprisingly high, but that might be because when we think about our own life, our close ones, and all the things we see in the news and know about other countries and cultures, it makes little difference whether all of civilization ends and a few humans survive, or whether all of civilization ends and no one survives. So when experts talk about e.g. the dangers of nuclear war, they may focus on the “this could very well end civilization” aspects, without emphasizing the part that some few humans at least are probably going to survive. And after the worst part is survived, population growth could kick in again and, even though the absence of fossil fuels in such a scenario would likely mean that technological progress takes longer, this “disadvantage” could quite plausibly be overcome given longer timescales and larger populations per level of technology (closer to the Malthusian limits). (back)
- One pathway for positive spillover effects would be if increased global coordination with respect to non-AI technologies also improves important coordination efforts for the development of smarter-than-human AI systems. And maybe lower risks of catastrophes generally lead to a more stable geopolitical climate where arms races are less pronounced, which could be highly beneficial for s-risk reduction. See also the points made here. (back)
- Furthermore, because a scenario where civilization collapsed would already be irreversibly very bad for all the people who currently exist or would exist at that time, making an eventual recovery more likely (after several generations of post-Apocalyptic hardship) would suddenly become something that is only favored by some people’s altruistic concerns for the long-term future, and not anymore by self-oriented or family- or community-oriented concerns. (back)
- I think the situation is such that extremely few positions are comfortable with the thought of extinction, but also few perspectives come down to regarding the avoidance of extinction as top priority. In this podcast, Toby Ord makes the claim that non-consequentialist value systems should place particular emphasis on making sure humanity does not go extinct. I agree with this only to the small extent that it is true that such views largely would not welcome extinction. However, overall I disagree and think it is hasty to pocket these views as having extinction-risk reduction as their primary priority. Non-consequentialist value systems admittedly are often somewhat underdetermined, but insofar as they do say anything about the long-term future being important, it strikes me as a more natural extension to count them as extinction-averse but downside-focused rather than extinction-averse and upside-focused. I think this would be most pronounced when it comes to downside risks by action, i.e. moral catastrophes humanity could be responsible for. A central feature distinguishing consequentialism from other moral theories is that the latter often treat harmful actions differently from harmful omissions. For instance, a rights-based theory might say that it is particularly important to prevent large-scale rights violations in the future (‘do no harm’), though not particularly important to make large-scale positive scenarios actual (‘create maximal good’). The intuition that causes some people to walk away from Omelas, in this fictional dilemma that is structurally similar to some of the moral dilemmas we might face regarding the promises and dangers from advanced technology and space colonization, are largely non-consequentialist intuitions. Rather than fighting for Omelas, I think many non-consequentialist value systems would instead recommend a focus on helping those beings who are (currently) worst-off, and perhaps (if one extends the scope of such moralities to also include the long-term future) also a focus on helping to prevent future suffering and downside risks. (back)
- For a pointer on how to roughly envision such a scenario, I recommend this allegorical description of a future where humans lose their influence over an automated economy. (back)
- See the description under Problem #2 here. (back)
- Of course, every decent person has intrinsic concern for avoiding the worst failure modes in AI alignment, but the difference is that, from a downside-focused perspective, bringing down the probabilities from very small to extremely small is as important as it gets, whereas for upside-focused views, other aspects of AI alignment may look more promising to work on (on the margin) as soon as the obvious worst failure modes are patched. (back)
- Valuing reflection means to value not one’s current best guess about one’s (moral) goals, but what one would want these goals to be after a long period of philosophical reflection under idealized conditions. For instance, I might envision placing copies of my brain state now into different virtual realities, where these brain emulations get to converse with the world’s best philosophers, have any well-formed questions answered by superintelligent oracles, and, with advanced technology, explore what it might be like to go through life with different moral intuitions, or explore a range different experiences. Of course, for the reflection procedure to give a well-defined answer, I would have to also specify how I will get a moral view out of whatever the different copies end up concluding, especially if there won’t be a consensus or if the consensus strongly depends on ordering effects of the thought experiments being presented. A suitable reflection procedure would allow the right amount of flexibility in order to provide us with a chance of actually changing our current best guess morality, but at the same time, that flexibility should not be dialed up too high, as this might then fail to preserve intuitions or principles we are – right now – certain we would want to preserve. The art lies in setting just the right amount of guidance, or selecting some (sub)questions where reflection is welcome, and others (such as maybe whether we want to make altruism a major part of our identity or instead go solely with rational egoism, which after all also has sophisticated philosophical adherents) that are not open for change. Personally, I find myself having much stronger and more introspectively transparent or reasoning-backed intuitions about population ethics than e.g. the question of which entities I morally care about, or to what extent I care about them. Correspondingly, I am more open for changing my mind on the latter. I would be more reluctant to trust my own thoughts and intuitions on population ethics if I thought it is likely that there was a single correct solution. However, based on my model of how people form consequentialist goals – which are a new and weird thing for animal minds to get hijacked by – I feel confident that at best, we will find several consistent solutions that serve as attractors for humans undergoing sophisticated reflection procedures, but no voluntarily-consulted reflection procedure can persuade someone to adopt a view that they rule out as something they would ex ante not want the selection procedure to select for them. (back)
- An alternative to the parliamentary approach that is sometimes mentioned, at least for dealing with moral uncertainty between consequentialist views that seem comparable, would be to choose whichever action makes the largest positive difference in terms of expected utility between views, or choose the action for which “more seems at stake.” While I can see some intuitions (related to updatelessness) for this approach, I find it overall not very convincing because it so strongly and predictably privileges upside-focused views, so that downside-focused views would get virtually no weight. For a related discussion (which may only make sense if people are familiar with the context of multiverse-wide cooperation) on when the case for updatelessness becomes particularly shaky, see the section “Updateless compromise” here. Altogether, I would maybe give some weight to expected value considerations for dealing with moral uncertainty, but more weight to a parliamentary approach. Note also that the expected value approach can create moral uncertainty wagers for idiosyncratic views, which one may be forced to accept for reasons of consistency. Depending on how one defines how much is at stake according to a view, an expected value approach in our situation gives the strongest boost to normatively upside-focused views such as positive utilitarianism (“only happiness counts”) or to views which affect as many interests as possible (such as counting the interests of all possible people, which under some interpretations should swamp every other moral consideration by the amount of what is at stake). (back)
- Both Kant and Parfit noticed that one’s decisions may change if we regard ourselves as deciding over not just our own policy over actions, but over a collective policy shared by agents similar to us. This principle is taken up more formally by many of the alternatives to causal decision theory that recommend cooperation (under varying circumstances) even in one-shot, prisoner-dilemma-like situations. In On What Matters (2011), Parfit in addition argued that the proper interpretation for both Kantianism and consequentialism suggests that they are describing the same kind of morality, “Kantian” in the sense that naive acts-justify-the-means reasoning often does not apply, and consequentialist in that, ultimately, what matters is things being good. (back)
- I am primarily talking about people we can interact with, though some approaches to thinking about decision theory suggest that potential allies may also include people in other parts of the multiverse, or future people good at Parfit’s Hitchhiker problem. (back)